
Multilayer Perceptron and Learning
Advanced Topics in Machine Learning for Bioinformatics and Biomedical Engineering
Dr. Alexandre Perera Lluna 
March 9, 2026
What a neuron/layer computes
A single unit (neuron) takes an input vector \(x \in \mathbb{R}^d\), computes:
- Linear step (logit / pre-activation)
\[ z = w^\top x + b \] - Output (activation)
\[ a = \phi(z) \]

The big picture

A classical neural network
MSE vs MAE vs Huber
BCE as a function of logit

Cross-entropy vs margin for the correct class

BCE vs focal loss (binary)

Chain rule in one line
Backprop = applying the chain rule along the edges of a graph. \[ a = w^\top x + b,\qquad \hat{y}=\sigma(a)=\frac{1}{1+e^{-a}} \]
\[ L(\hat{y},y) = -\left(y\log \hat{y} + (1-y)\log(1-\hat{y})\right) \]
If \(L\) depends on \(\hat{y}\), which depends on \(a\), which depends on \(w\):

Visual intuition: derivatives of common activations


Backprop as “messages” (reverse-mode autodiff)
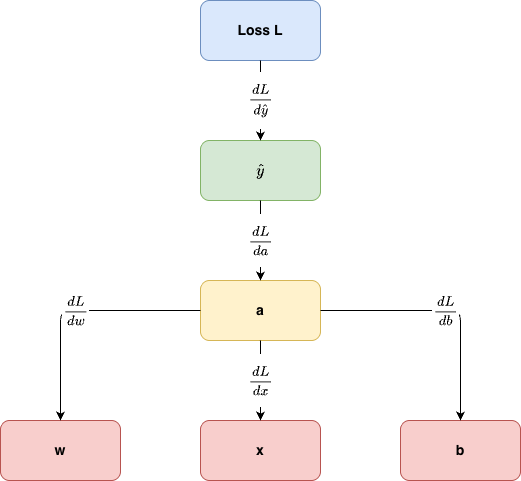
During the backward pass each node receives an upstream gradient \[ \bar{v} := \frac{\partial L}{\partial v} \] and sends downstream gradients to its parents.
Identity (Linear)
\[ \phi(x) = x \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \(\mathbb{R}\)
- Differentiable everywhere; \(\phi'(x)=1\)
- Monotone increasing, no saturation
- Used mainly as the final layer for regression (e.g., predicting expression levels as real values)

Sigmoid (Logistic)
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \((0,1)\) (interpretable as a probability)
- Smooth and differentiable everywhere
- Derivative: \[ \sigma'(x) = \sigma(x)\,[1-\sigma(x)] \]
- Saturates for large \(|x|\) \(\Rightarrow\) vanishing gradients
- Commonly used for binary classification outputs (e.g., disease vs control)

Hyperbolic Tangent (tanh)
\[ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \((-1,1)\) (zero-centered outputs often help optimization vs sigmoid)
- Smooth and differentiable everywhere
- Derivative: \[ \frac{d}{dx}\tanh(x) = 1 - \tanh^2(x) \]
- Saturates for large \(|x|\) \(\Rightarrow\) vanishing gradients
- Historically common in hidden layers and RNNs; now often replaced by ReLU-family activations

ReLU (Rectified Linear Unit)
\[ \mathrm{ReLU}(x) = \max(0, x) \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \([0,\infty)\)
- Piecewise linear; derivative: \[ \mathrm{ReLU}'(x)= \begin{cases} 0 & x < 0 \\ 1 & x > 0 \end{cases} \] (At \(x=0\) it is not differentiable; in practice, a subgradient is used.)
- fast, encourages sparse activations, mitigates vanishing gradients on \(x>0\)
- Dying ReLU — if a unit stays at \(x<0\), its gradient is 0 and it may stop learning

Leaky ReLU
\[ \phi(x)= \begin{cases} x & x\ge 0 \\ \alpha x & x<0 \end{cases} \quad \text{with } \alpha \in (0,1) \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \(\mathbb{R}\)
- Piecewise linear, not differentiable at 0 (handled with subgradients)
- Derivative: \[ \phi'(x)= \begin{cases} 1 & x>0 \\ \alpha & x<0 \end{cases} \]
- Reduces dying ReLU by allowing a small gradient when \(x<0\)

ELU (Exponential Linear Unit)
\[ \mathrm{ELU}(x)= \begin{cases} x & x\ge 0 \\ \alpha\left(e^x - 1\right) & x<0 \end{cases} \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \((-\alpha,\infty)\)
- Smooth on \(x<0\), continuous everywhere; often chosen \(\alpha=1\)
- Derivative: \[ \mathrm{ELU}'(x)= \begin{cases} 1 & x>0 \\ \alpha e^x & x<0 \end{cases} \]
- Negative outputs can help keep activations closer to zero mean (sometimes improving optimization)

Softplus (Smooth ReLU)
\[ \mathrm{Softplus}(x)=\ln\left(1+e^x\right) \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \((0,\infty)\)
- Smooth approximation to ReLU
- Derivative: \[ \frac{d}{dx}\mathrm{Softplus}(x)=\sigma(x) \]
- For very negative \(x\), gradients become small (still some saturation), but it avoids the hard link at 0

GELU (Gaussian Error Linear Unit)
A common approximation used in practice is:
\[ \mathrm{GELU}(x) \approx \frac{1}{2}x\left[1+\tanh\left(\sqrt{\frac{2}{\pi}}(x+0.044715x^3)\right)\right] \]
Properties
- Domain: \(\mathbb{R}\)
- Range: \(\mathbb{R}\)
- Smooth, non-monotonic near the origin (it can slightly down-weight small negative inputs)
- Common in Transformers and other modern architectures
- More computationally expensive than ReLU/Leaky ReLU

Softmax (Multi-class output)
For logits \(\mathbf{z} \in \mathbb{R}^K\),
\[ \mathrm{Softmax}(z_i)=\frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \]
Properties
- Domain: \(\mathbb{R}^K\)
- Range: \((0,1)^K\) with \(\sum_i p_i = 1\)
- Outputs are probabilities: each in \((0,1)\) and \(\sum_i p_i = 1\)
- Invariant to adding a constant: \[ \mathrm{Softmax}(\mathbf{z})=\mathrm{Softmax}(\mathbf{z}+c) \]
- Needs numerical stability: compute with \(\mathbf{z}-\max(\mathbf{z})\)
- Typical use: multi-class classification output layer

All of them


Underfit — model too simple
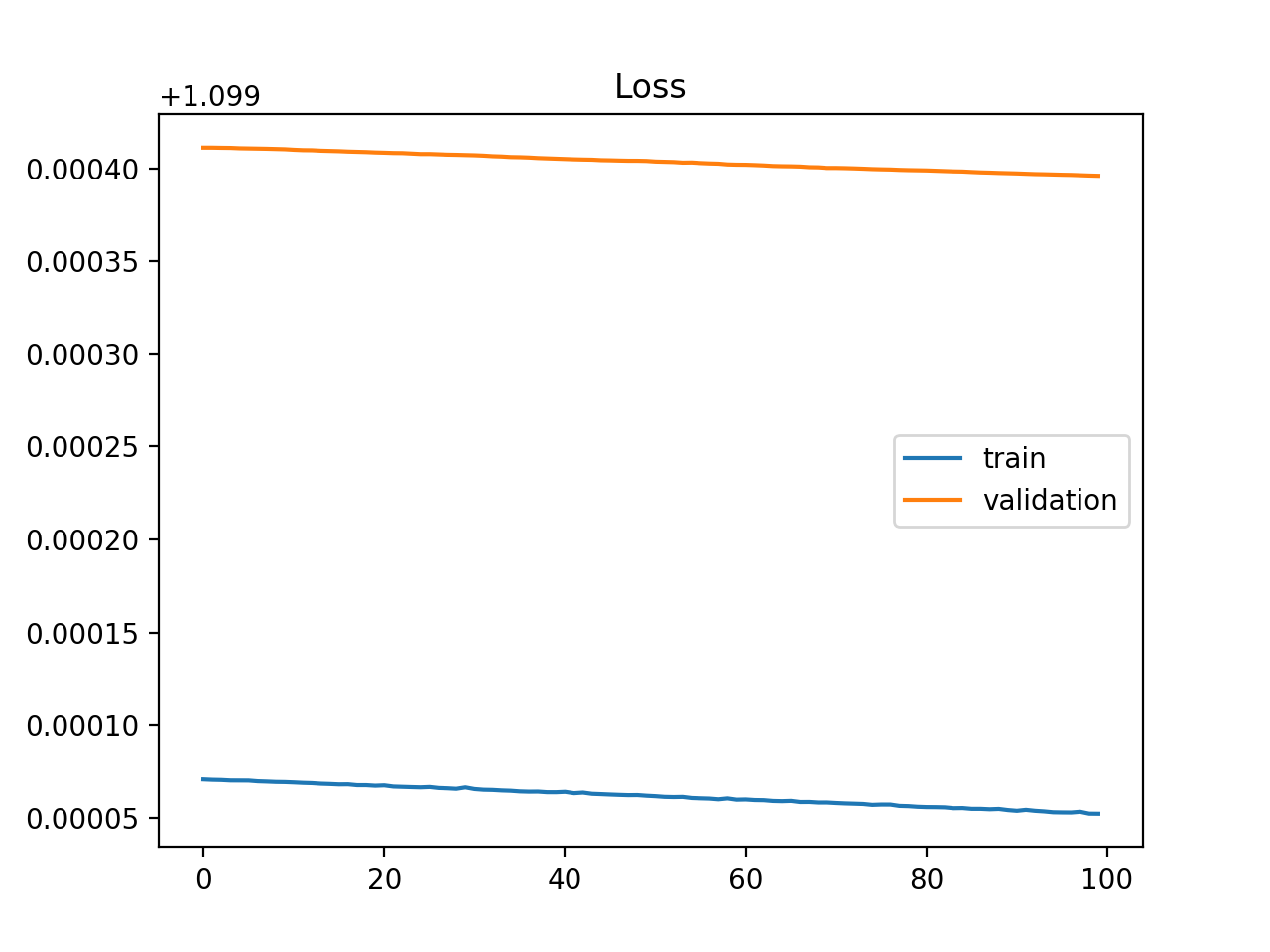
Flat curves at high loss
The model does not have sufficient capacity for the complexity of the dataset.
Causes:
- Model too simple (too few parameters / layers)
- Features not expressive enough
- Learning rate too high
Remedy: increase model capacity, add layers, or improve features.
Underfit — training stopped too early
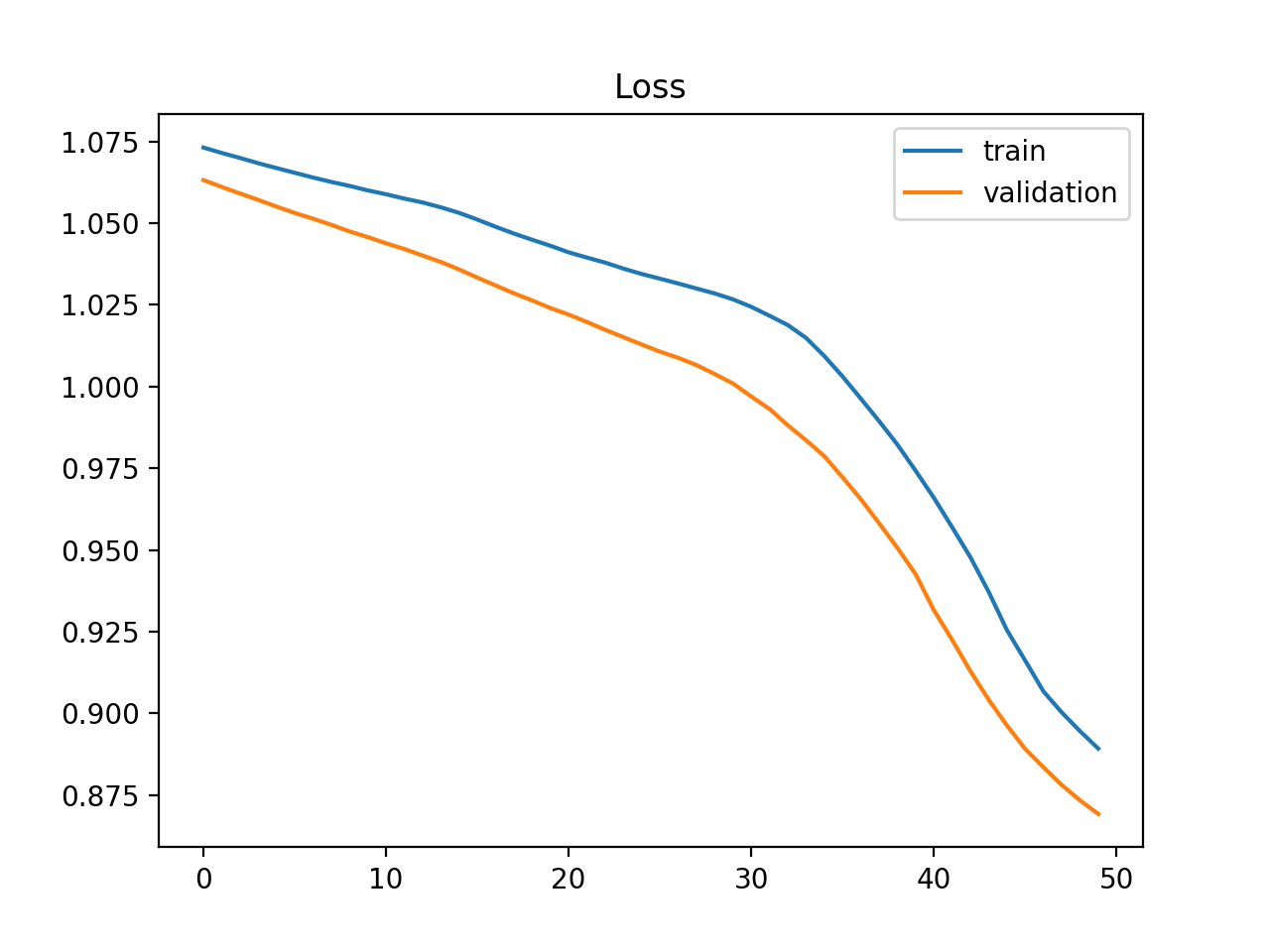
Dec. Train loss · Dec. Val loss
Both curves are still falling — the model has capacity to keep improving but training was stopped prematurely.
Causes:
- Too few epochs
- Very aggressive early stopping criterion
Remedy: train for more epochs; revisit early-stopping patience.
Overfit

Dec. Train loss · Inc. Val loss
Training loss keeps decreasing while validation loss starts to increase — a clear sign the model is memorising rather than learning.
Remedies:
- Regularisation (L2, dropout)
- Data augmentation
- Reduce model capacity
- Early stopping at the divergence point
Good Fit
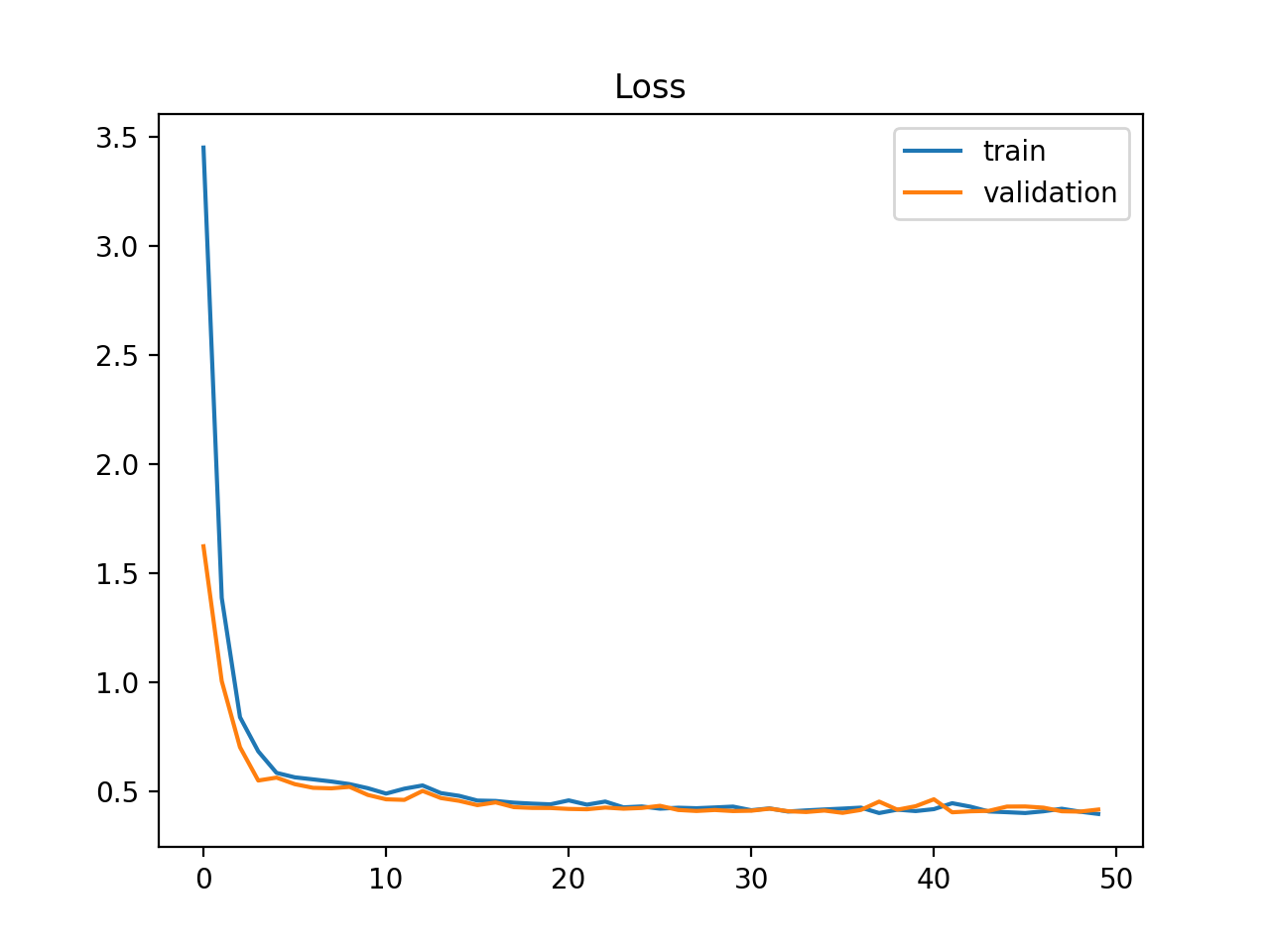
Stable Train loss · Stable Val loss
- Training loss decreases and stabilises \(\checkmark\)
- Validation loss follows a similar path \(\checkmark\)
- Both reach a similar final value \(\checkmark\)
A small, stable gap between train and val loss is acceptable — a perfect gap of zero is unlikely in practice.
Unrepresentative Training Set
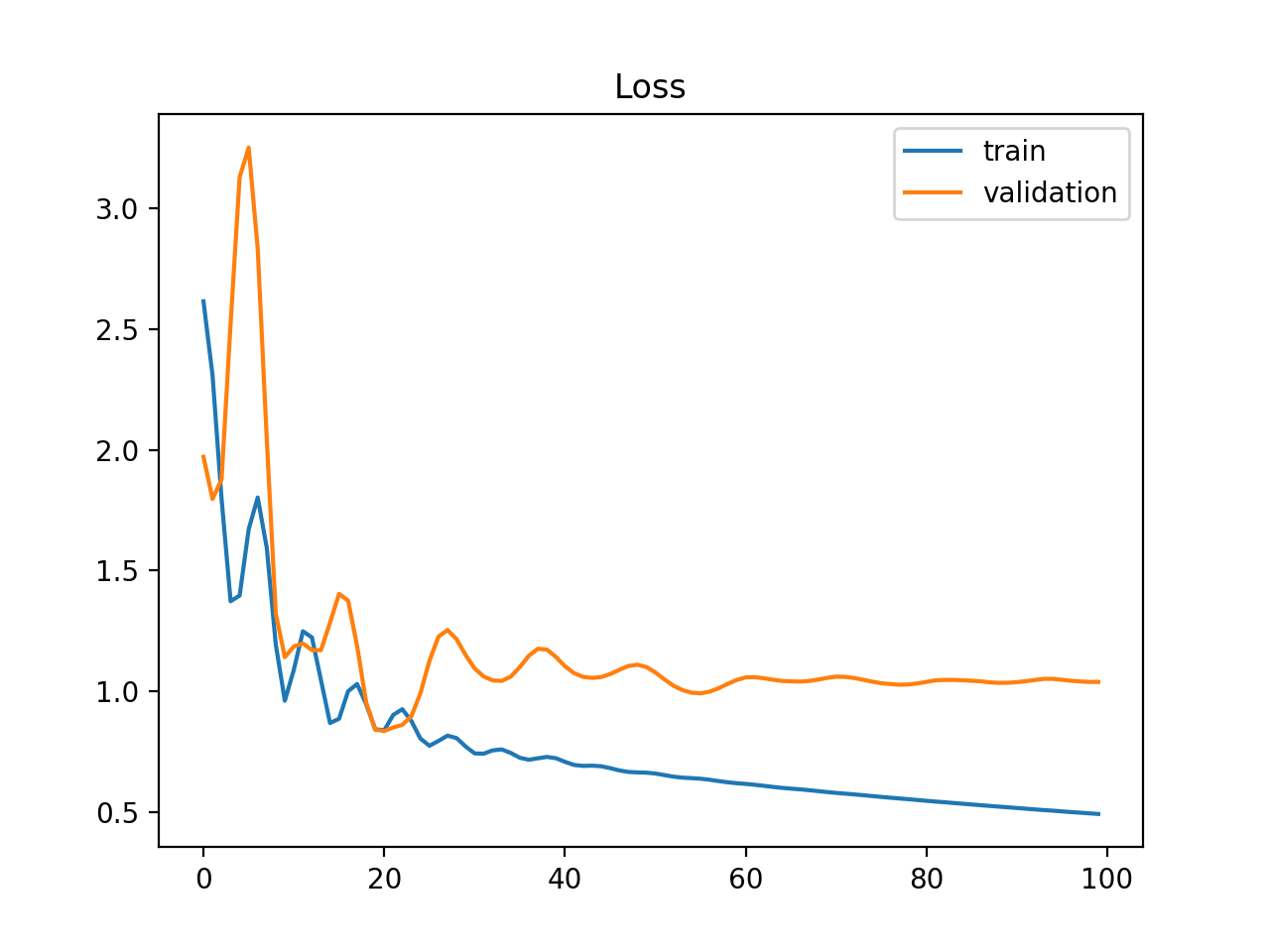
Dec. Train loss · Stable Val loss · Growing gap
- Training loss decreases steadily
- Validation loss stabilises at a much higher value
- The gap between the two curves widens over time
Remedies:
- Collect more training data
- Apply data augmentation
- Check for train/val distribution mismatch
Unrepresentative Validation Set — noisy

Stable Train loss · Noisy Val loss
- Training loss looks like a good or acceptable fit
- Validation loss shows high variance — erratic behaviour with no clear trend
Causes:
- Validation set too small
- Validation set not stratified / shuffled
Remedy: increase validation set size; use k-fold cross-validation.
Unrepresentative Validation Set — val below train

Stable Train loss · Lower Val loss · Wide gap
- Training loss looks like a good fit
- Validation loss converges to a value lower than training loss
- The gap is persistent and wide
Common cause: dropout or other stochastic regularisation active during training but disabled during evaluation, making val loss artificially lower.
Not always a problem — understand the cause first.
Why overfitting matters in bioinformatics (and everywhere)
A deep model can look brilliant on the training set and still be useless on new samples.
Think about a classifier trained to distinguish tumour subtypes from gene-expression profiles. If the network learns quirks of the training cohort rather than stable biological patterns, it will not generalise to patients from another lab, hospital, or sequencing batch.
\[ \mathcal{L}_{\text{train}} \downarrow \quad \text{while} \quad \mathcal{L}_{\text{val}} \uparrow \]
\[ \text{generalisation gap} = \mathcal{L}_{\text{val}} - \mathcal{L}_{\text{train}} \]
Note
A widening gap between training and validation loss is the classic warning sign: the model is remembering the data, not learning the signal.
Tip
In biology this is especially dangerous — datasets are often small, noisy, high-dimensional, and heterogeneous.
A healthy model improves on both sets; an overfit model keeps improving only on training data.
Recap
NN
Dropout

About dropout
A sensible recipe in practice
Start simple
Use a model no larger than necessary. In small biological datasets, architecture size matters as much as clever regularisation.
Combine techniques
A common recipe is weight decay + early stopping, with dropout added if the dense layers are clearly overfitting.
Validate honestly
Split by patient, experiment, or batch — not by random rows. In bioinformatics, leakage hides in the structure of the data.
Practical checklist
- Watch both training and validation curves throughout training.
- Tune \(\lambda\), dropout rate, and patience on validation data — never on the test set.
- Prefer biologically plausible augmentation strategies.
- Be suspicious of near-perfect training accuracy on a small dataset.
- Interpret success in terms of generalisation, not memorisation.
Note
The most important idea is not a specific trick. It is the habit of asking: “Will this model still work on new biological samples?”
