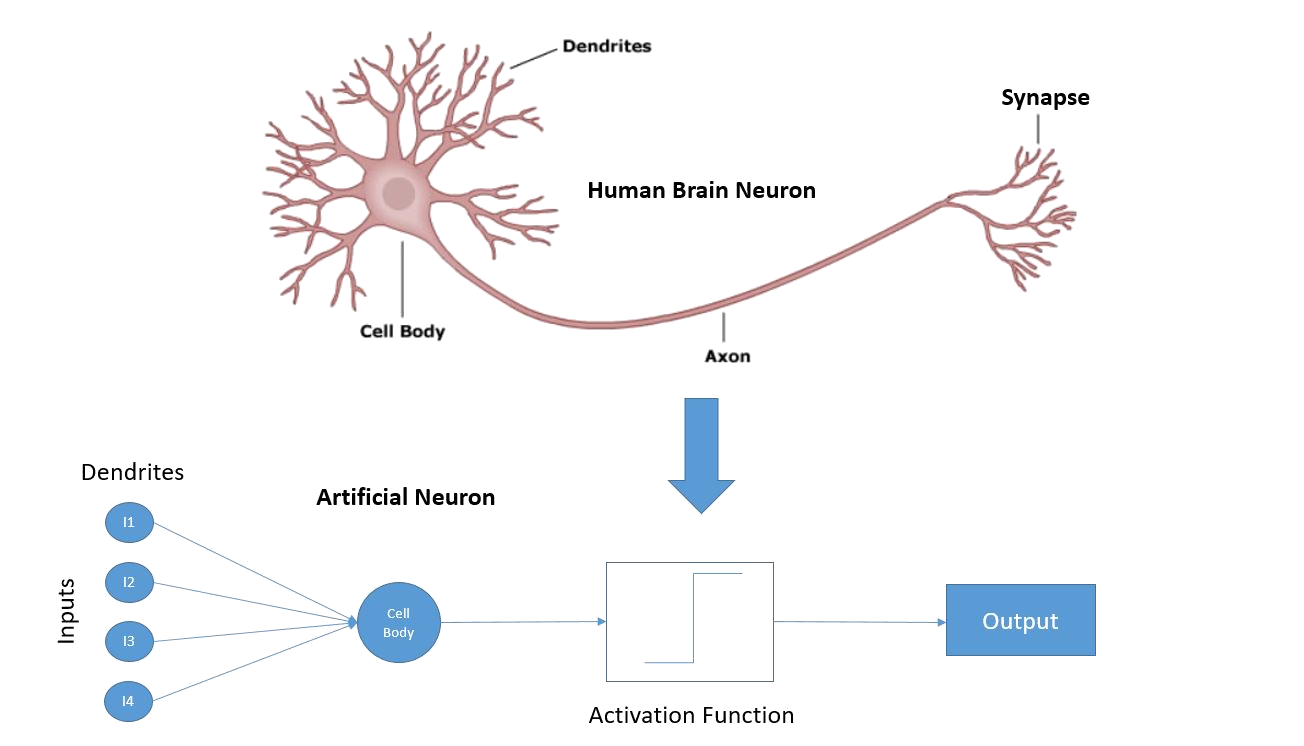
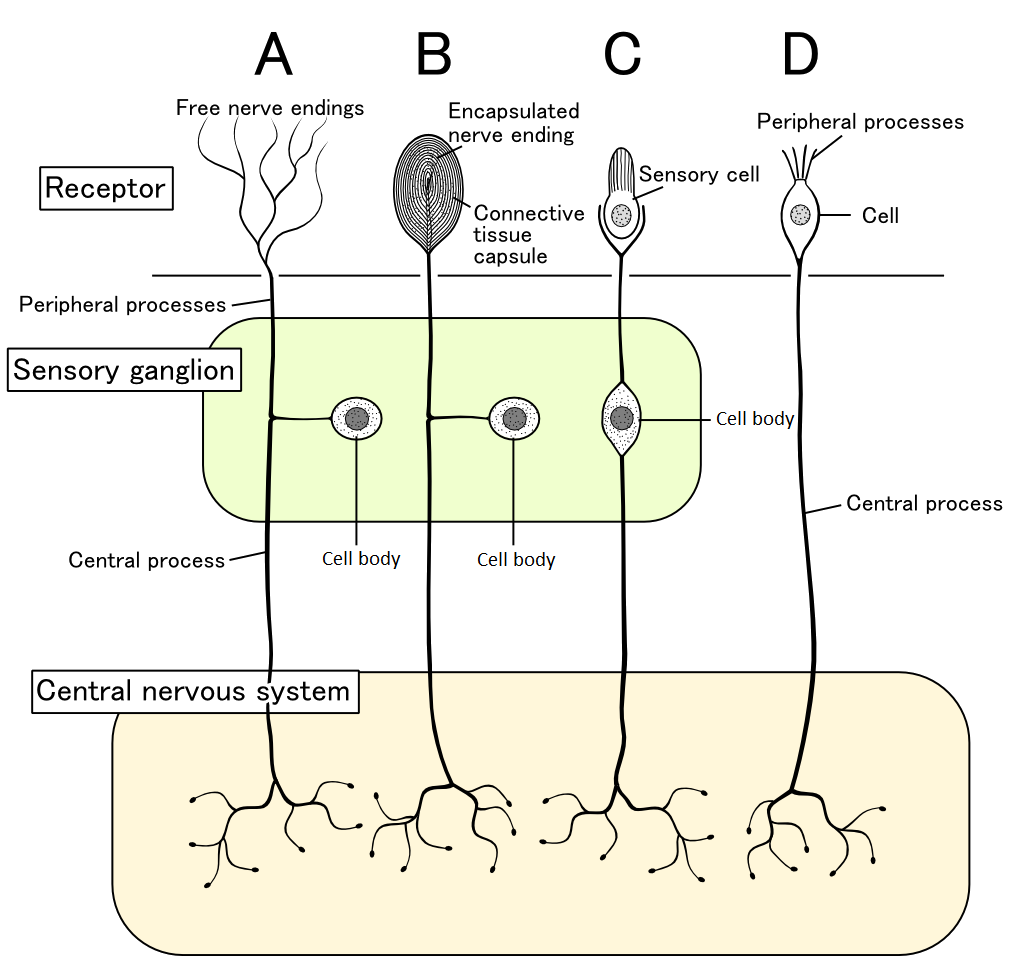
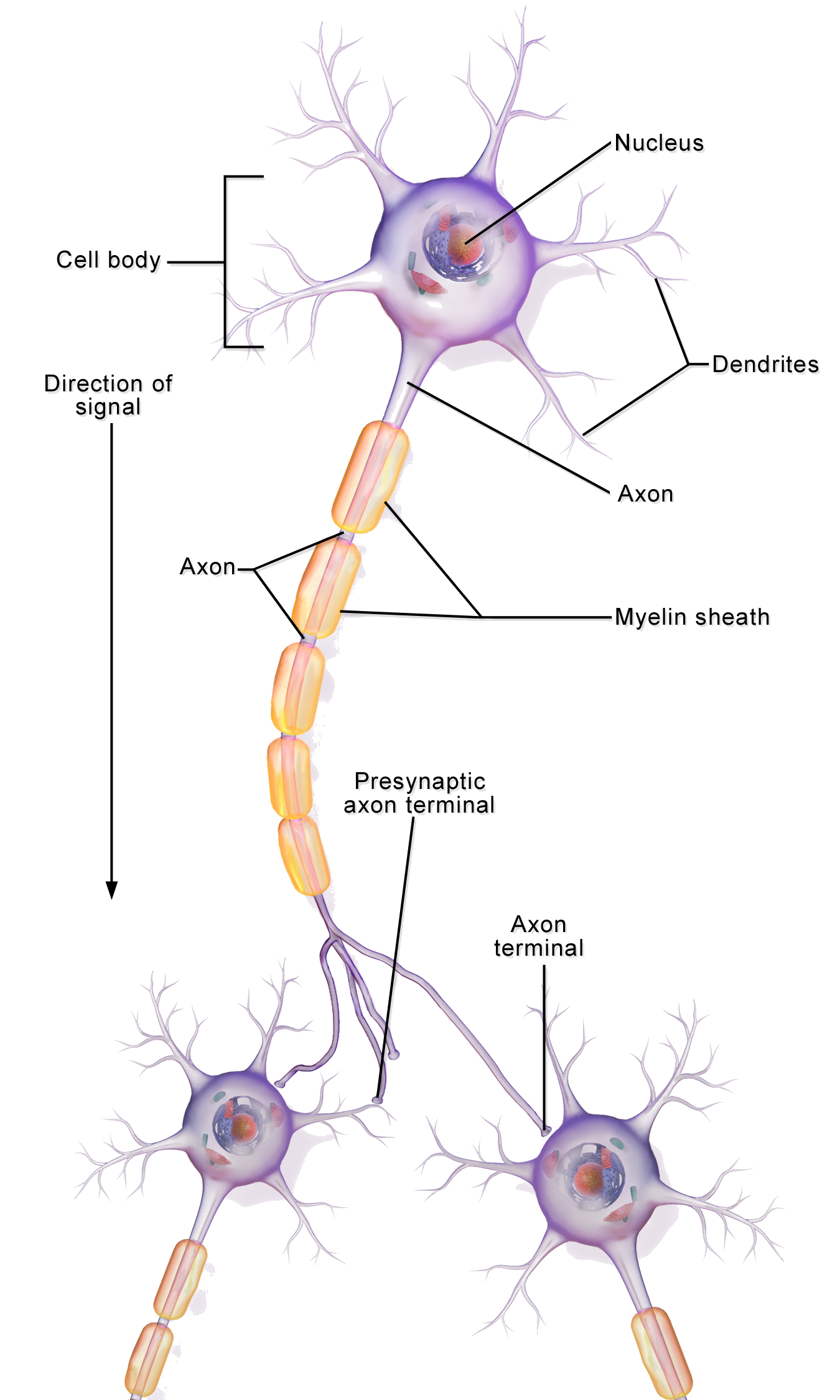
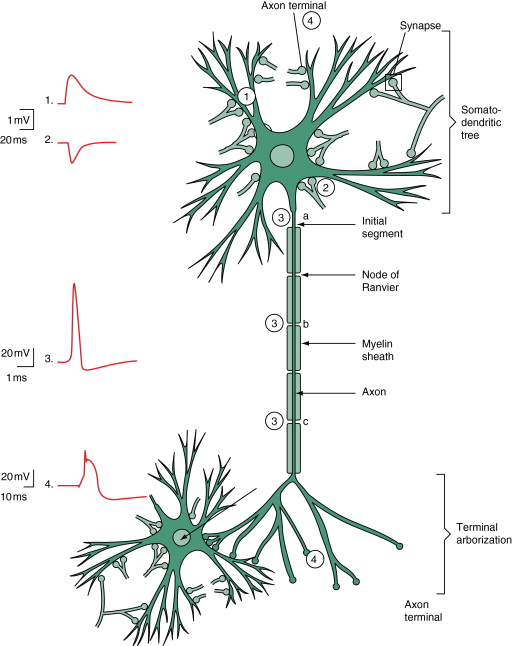
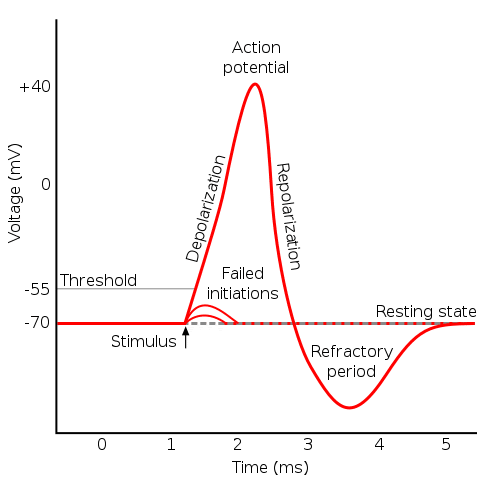
Biological Motivation
- Neurons communicate via action potentials (spikes).
- Learning corresponds to changes in synaptic weights.
Hebbian Learning
Assume a simple model of a neuron \(j\), represented as
\[
y_j = \mathbf{w_j}^\top \mathbf{x}
\]
\[
\Delta w_{ij} = \eta y_j x_i
\]
\[
\Delta \mathbf{w_{j}} = \eta \, ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x}
\]
If we use a set of data patterns for learning \(\mathbf{S}\): \[
\Delta \mathbf{w_{j}} = \sum_s ( \mathbf{w_j}^\top \mathbf{x^s} ) \mathbf{x^s} \equiv \eta \langle ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x} \rangle_S
\]
Hebbian Learning
- Weight update proportional to pre- and post-synaptic activity:
\[
\Delta w_{ij} = \eta \, x_i \, y_j
\]
\(x_i\) : presynaptic activity
\(y_j\) : postsynaptic activity
\(\eta\): learning rate
Vector form for one postsynaptic unit with input vector \(\mathbf{x}\) and output \(y\):
\[
\Delta \mathbf{w} = \eta \, y \, \mathbf{x}
\]
- Problem is that weights grow without bound.
Hebbian Learning
\[
\Delta \mathbf{w_{j}} = \eta \langle ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x} \rangle_S
\]
![]()
Hebbian Learning
\[
\Delta \mathbf{w_{j}} = \eta \langle ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x} \rangle_S
\]
![]()
Hebbian Learning
\[
\Delta \mathbf{w_{j}} = \eta \langle ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x} \rangle_S
\]
Hebbian Learning
\[
\Delta \mathbf{w_{j}} = \eta \langle ( \mathbf{w_j}^\top \mathbf{x} ) \mathbf{x} \rangle_S
\]
Hebb II — Consequences and Normalization
- Correlation seeking: weights align with input directions that co-vary with \(y\).
- Unbounded growth without constraints:
\[
\lVert \mathbf{w}_{t+1} \rVert^2
= \lVert \mathbf{w}_t \rVert^2 + 2\eta\, y\, \mathbf{w}_t^\top \mathbf{x} + \eta^2 y^2 \lVert \mathbf{x} \rVert^2
\]
- Practical stabilizations:
- Weight clipping: \(w_{ij} \leftarrow \mathrm{clip}(w_{ij}, w_{\min}, w_{\max})\)
- Weight decay: \(\Delta w_{ij} = \eta \, x_i \, y_j - \lambda w_{ij}\)
- Post-update normalization: \(\mathbf{w} \leftarrow \mathbf{w}/\lVert \mathbf{w} \rVert\)
- Oja’s modification (for comparison): \(\Delta w_{ij} = \eta \, y \, (x_i - y \, w_{ij})\)
Oja’s Rule
- Modification of Hebbian rule with normalization:
\[
\Delta w_{ij} = \eta \, y_j \, (x_i - y_j w_{ij})
\]
- Prevents weight divergence.
Oja’s Rule I: normalization effect
\[
\Delta w_{i} = \eta \, y \, (x_i - y w_{i})
\]
- For the case \(\qquad (y \ll 1)\)
\[
\Delta w_{i} = \eta \, y \, \bigl(x_i - \cancel{y w_{i}}\bigr) = \eta y x_i
\]
- For the case \(\qquad (y \gg 1)\)
\[
\Delta w_{i} = \eta \, y \, \bigl(\cancel{x_i} - y w_{i}\bigr) = - \eta y^2 w_i
\]
Stability analysis for Oja’s correction
\[
y = \mathbf{w}^\top \mathbf{x}
\]
\[
\eta^{-1} \Delta \mathbf{w} = y \mathbf{x} - y^2 \mathbf{w}
\]
We can evaluate three aspects of the Oja correction:
- How do the weights evolve as we train ?
- Which are the stationary values of the weights ?
- Which weights vectors are stable ?
How do the weights evolve as we train ?
Let’s simplify a bit the update rule
\[
\begin{eqnarray}
\eta^{-1} \Delta \mathbf{w} &=& \langle y \mathbf{x} - y^2 \mathbf{w} \rangle \\
&=& \langle ( \mathbf{w}^\top \mathbf{x}) \mathbf{x} - ( \mathbf{w}^\top \mathbf{x})^2 \mathbf{w} \rangle \\
&=& \langle \mathbf{x} ( \mathbf{w}^\top \mathbf{x}) - ( \mathbf{w}^\top \mathbf{x}) ( \mathbf{w}^\top \mathbf{x}) \mathbf{w} \rangle \\
&=& \langle \mathbf{x} ( \mathbf{x}^\top \mathbf{w}) - ( \mathbf{w}^\top \mathbf{x}) ( \mathbf{x}^\top \mathbf{w}) \mathbf{w} \rangle \\
&=& \langle ( \mathbf{x} \mathbf{x}^\top ) \mathbf{w} - ( \mathbf{w}^\top ( \mathbf{x} \mathbf{x}^\top ) \mathbf{w}) \mathbf{w} \rangle \\
&=& \langle \mathbf{x} \mathbf{x}^\top \rangle \mathbf{w} - ( \mathbf{w}^\top \langle \mathbf{x} \mathbf{x}^\top \rangle \mathbf{w}) \mathbf{w} \\
&=& C \mathbf{w} - ( \mathbf{w}^\top C \mathbf{w}) \mathbf{w} \\
\end{eqnarray}
\]
\[
\eta^{-1} \Delta \mathbf{w} = (C-\mathbf{w}^\top C \mathbf{w} ) \mathbf{w}
\]
Which are the stationary values of the weights ?
Given by \[
\eta^{-1} \Delta \mathbf{w} = 0
\] So \[
C\mathbf{w} = (\mathbf{w}^\top C \mathbf{w} ) \mathbf{w}
\] if we define \(\lambda = \mathbf{w}^\top C \mathbf{w}\) we retreive a standard eigenvalues problem: \[
C\mathbf{w} = \lambda \mathbf{w}
\] in which we see that
\[
\lambda = \mathbf{w}^\top C \mathbf{w} = \mathbf{w}^\top \lambda \mathbf{w} = \lambda ||\mathbf{w} ||^2
\]
So in stationary case the norm of \(\mathbf{w}\) must be 1.
Which are the stationary values of the weights ?
In summary, in stationary values of the weights \(\eta^{-1} \langle \Delta \mathbf{w} = 0 \rangle\):
- In stationary case the norm of \(\mathbf{w}\) must be 1 .
- \(C\mathbf{c_k} = \lambda_k \mathbf{c_k}\)
Which weights vectors are stable ?
We have this dynamics: \[
\eta^{-1} \Delta \mathbf{w} = C\mathbf{w} - (\mathbf{w}^\top C \mathbf{w} ) \mathbf{w}
\]
Then, we can perturbate \(\mathbf{w}\) around \(e_\alpha\) to see its dynamics stability points:
\[
\mathbf{w} = e_\alpha + \varepsilon
\]
Substitute into \(\eta^{-1} \Delta \mathbf{w}\)
Which weights vectors are stable I?
Substitute into \(\eta^{-1} \Delta \mathbf{w}\), you will find1: \[
\begin{aligned}
\eta^{-1}\Delta \mathbf{w}
&= C(e_\alpha+\varepsilon)
-\bigl((e_\alpha+\varepsilon)^\top C(e_\alpha+\varepsilon)\bigr)(e_\alpha+\varepsilon) \\
&= (Ce_\alpha + C\varepsilon)
-\Bigl(e_\alpha^\top C e_\alpha + e_\alpha^\top C\varepsilon + \varepsilon^\top C e_\alpha + \varepsilon^\top C\varepsilon\Bigr)(e_\alpha+\varepsilon) \\
&= Ce_\alpha + C\varepsilon
-(e_\alpha^\top C e_\alpha)e_\alpha
-(e_\alpha^\top C e_\alpha)\varepsilon
-(e_\alpha^\top C\varepsilon)e_\alpha
-(\varepsilon^\top C e_\alpha)e_\alpha
+ \mathcal{O}(\|\varepsilon\|^2) \\
&= \lambda_\alpha e_\alpha + C\varepsilon
-\lambda_\alpha e_\alpha
-\lambda_\alpha \varepsilon
-(e_\alpha^\top C\varepsilon)e_\alpha
-(\varepsilon^\top C e_\alpha)e_\alpha
+ \mathcal{O}(\|\varepsilon\|^2) \\
&= (C-\lambda_\alpha I)\varepsilon
-\Bigl(e_\alpha^\top C\varepsilon+\varepsilon^\top C e_\alpha\Bigr)e_\alpha
+ \mathcal{O}(\|\varepsilon\|^2) \\
&= (C-\lambda_\alpha I)\varepsilon
-2\lambda_\alpha (e_\alpha^\top \varepsilon)\,e_\alpha
+ \mathcal{O}(\|\varepsilon\|^2),
\end{aligned}
\]
Which weights vectors are stable ?
\[
\eta^{-1}\Delta \mathbf{w} = (C-\lambda_\alpha I)\varepsilon
-2\lambda_\alpha (e_\alpha^\top \varepsilon)\,e_\alpha
+ \mathcal{O}(\|\varepsilon\|^2)
\]
![]()
Which weights vectors are stable I?
We can simplify by projecting againt one eigenvector \(e_\beta\); \[
\begin{aligned}
\eta^{-1} e_\beta^\top \Delta \varepsilon
&\approx e_\beta^\top\Bigl[(C-\lambda_\alpha I)\varepsilon
-2\lambda_\alpha (e_\alpha^\top \varepsilon)\,e_\alpha\Bigr] \\[4pt]
&= e_\beta^\top C\varepsilon
-\lambda_\alpha e_\beta^\top \varepsilon
-2\lambda_\alpha (e_\alpha^\top \varepsilon)\, e_\beta^\top e_\alpha \\[4pt]
&= \lambda_\beta e_\beta^\top \varepsilon
-\lambda_\alpha e_\beta^\top \varepsilon
-2\lambda_\alpha (e_\alpha^\top \varepsilon)\,\delta_{\alpha\beta} \\[4pt]
&= (\lambda_\beta-\lambda_\alpha)\,e_\beta^\top \varepsilon
-2\lambda_\alpha \delta_{\alpha\beta}\, e_\alpha^\top \varepsilon \\[8pt]
&=
\begin{cases}
-2\lambda_\alpha\, e_\alpha^\top \varepsilon, & \beta=\alpha,\\[4pt]
(\lambda_\beta-\lambda_\alpha)\, e_\beta^\top \varepsilon, & \beta\neq \alpha.
\end{cases}
\end{aligned}
\]
Which weights vectors are stable (cont.)?
\[
\begin{aligned}
\eta^{-1} e_\beta^\top \Delta \varepsilon
&\approx \begin{cases}
-2\lambda_\beta\, e_\beta^\top \varepsilon, & \beta=\alpha,\\[4pt]
(\lambda_\beta-\lambda_\alpha)\, e_\beta^\top \varepsilon, & \beta\neq \alpha.
\end{cases}
\end{aligned}
\]
then:
\[
\begin{aligned}
e_\beta^\top \Delta \varepsilon
&= e_\beta^\top ( \varepsilon^{n+1} - \varepsilon^{n} ) \\
&= (e_\beta^\top \varepsilon)^{n+1} - (e_\beta^\top \varepsilon)^{n} ) \\
&= \Delta (e_\beta^\top \varepsilon)
\end{aligned}
\]
Which weights vectors are stable (cont.)?
let’s define: \[
\begin{aligned}
\mathbf{s}_\beta& := e_\beta^\top \varepsilon \\
\mathbf{\kappa}_{\alpha \beta}& :=
\begin{cases}
\eta (-2\lambda_\alpha) & \beta=\alpha,\\[4pt]
\eta^ (\lambda_\beta-\lambda_\alpha) & \beta\neq \alpha.
\end{cases}
\end{aligned}
\]
\[
\Delta \mathbf{s}_\beta \sim \mathbf{\kappa}_{\alpha \beta} \mathbf{s}_\beta
\]
So, we have three cases :)
First Case vector stability
Case 1 \(\begin{aligned} \beta &\neq \alpha \\ \lambda_\beta &< \lambda_\alpha\end{aligned}\)
\[
\eta^{-1} e_\beta^\top \Delta \varepsilon
\approx
\begin{cases}
-2\lambda_\beta\, e_\beta^\top \varepsilon, & \beta=\alpha,\\[4pt]
(\lambda_\beta-\lambda_\alpha)\, e_\beta^\top \varepsilon, & \beta\neq \alpha.
\end{cases}
\]
- For \(\beta\neq \alpha\), since \(\lambda_\beta-\lambda_\alpha<0\), the component \(e_\beta^\top\varepsilon\) decays.
- This makes the direction \(e_\alpha\) stable against perturbations in lower-eigenvalue directions.
Second Case vector stability
Case 2 \(\begin{aligned} \beta &\neq \alpha \\ \lambda_\beta &> \lambda_\alpha\end{aligned}\)
\[
\eta^{-1} e_\beta^\top \Delta \varepsilon
\approx
(\lambda_\beta-\lambda_\alpha)\, e_\beta^\top \varepsilon
\]
- Now \(\lambda_\beta-\lambda_\alpha>0\), so \(e_\beta^\top\varepsilon\) grows.
- Any small perturbation toward a higher-eigenvalue direction gets amplified.
- Therefore \(e_\alpha\) is unstable if there exists any \(\beta\) with \(\lambda_\beta>\lambda_\alpha\).
Third Case vector stability
Case 3 \(\begin{aligned} \beta &\neq \alpha \\ \lambda_\beta &= \lambda_\alpha\end{aligned}\)
\[
\eta^{-1} e_\beta^\top \Delta \varepsilon
\approx
(\lambda_\beta-\lambda_\alpha)\, e_\beta^\top \varepsilon
= 0
\]
- No first-order push toward or away from \(e_\beta\): neutral stability along the degenerate subspace.
- The rule can converge to any unit vector in the eigenspace corresponding to \(\lambda_\alpha\).
- In practice, noise / initialization / higher-order terms decide the final direction.
Summary: stability of Oja’s rule
Decompose the weight direction around an eigenvector \(e_\alpha\) with \(\lambda_\alpha\):
- Perturbation along another eigenvector \(e_\beta\) evolves like \[e_\beta^\top \Delta\varepsilon \propto (\lambda_\beta-\lambda_\alpha)\,e_\beta^\top \varepsilon \quad (\beta\neq \alpha).\]
If \(\lambda_\beta < \lambda_\alpha\): perturbations shrink \(\Rightarrow\) \(e_\alpha\) is stable against lower-eigenvalue directions.
If \(\lambda_\beta > \lambda_\alpha\): perturbations grow \(\Rightarrow\) \(e_\alpha\) is unstable (pushed toward larger eigenvalues).
If \(\lambda_\beta = \lambda_\alpha\): perturbations are neutral \(\Rightarrow\) any direction in the degenerate eigenspace can persist.
Oja’s rule drives \(\mathbf{w}\) toward the principal eigenvector (largest \(\lambda\)); only the top-eigenvalue subspace is asymptotically stable.
Questions
![]()